In this first post, I'll look at subplots and annotations.
Turn off axes
We can remove axes, ticks, borders, etc. with
ax.axis('off').
This can be used to remove unnecessary subplots created with the subplots function
from pyplot,
for instance, when we only want to use the upper triangle of the grid. Here's an example:
The result is:

Share axes between subplots after plotting
An alternative way of making a ragged array of subplots makes use of
gridspec.
The problem here is that it is a bit more difficult to share x and y axes.
Of course add_subplot has keyword arguments sharex and sharey,
but then we have to distinguish between the first and subsequent subplots. A better solution is the
get_shared_x_axes() method. Here's an example:
The result is:

Hybrid (or blended) transforms for annotations
When you annotate a point in a plot, the location of the text is often relative to the data in one coordinate, but relative to the axis (e.g. in the middle) in the other. I used to do this with inverse transforms, but it turns out that there is a better way: the
blended_transform_factory function from matplotlib.transforms.
Suppose that I want to annotate three points in three subplots. The arrows should point to these three points, and I want the text to be located above the point, but the text in the 3 subplots has to be vertically aligned.
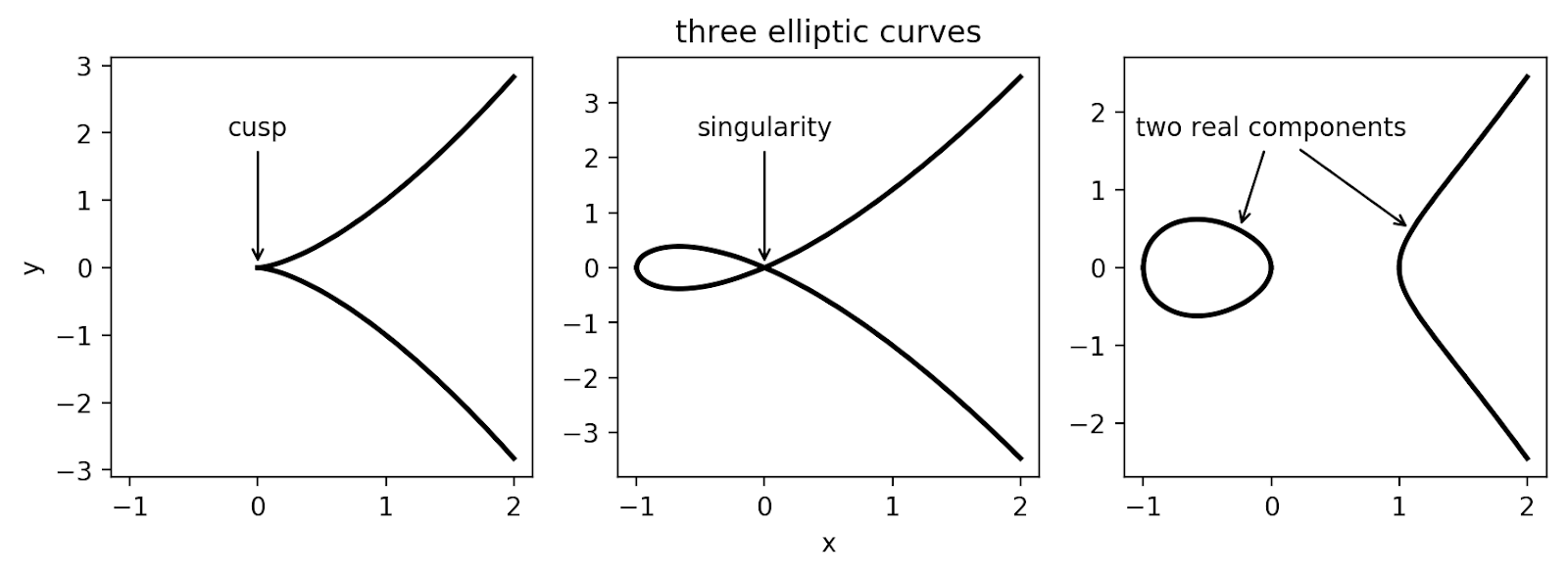
Notice that the y-axes are not shared between the subplots! To accomplish the alignment, we have to use the
annotate method with a custom transform.

